
Basics of AI
What is AI?
- In popular culture and fiction, the AI we see is generalized AI. It isn’t very realistic.
- A machine is said to have artificial intelligence if it can interpret data, potentially learn from the data and use that knowledge to adapt and achieve certain goals.
- A simple example of a computer with AI is detecting whether it is you in a photo or not.
- The concept was first realized in the Darthmouth conference 1956 but there was an AI winter due to a lack of computing power and data.
- These problems were solved with time (after ~2005) with more computing power and the internet.
Machine Learning Principles and Applications
Supervised Learning
- Computers to have to learn before they can do anything; just like humans.
- There are three main types of learning:
- Reinforcement Learning
- Unsupervised Learning
- Supervised Learning
- Reinforcement Learning: The process of learning in an environment through feedback from an AI’s behavior. Think about how a baby learns to walk; the baby keeps stumbling until one day he/she learns to balance and walk properly.
- Unsupervised Learning: The process of learning without training labels. It can also be called clustering or grouping.
- Supervised Learning: The process of learning with training labels. The supervisor knows the correct answer and points out mistakes during the learning process.
- An easy example would be to classify images of animals which are mammals or not. This AI needs to be trained by examples after which it should be able to classify images it hasn’t seen before. Another example is how spam emails are classified.
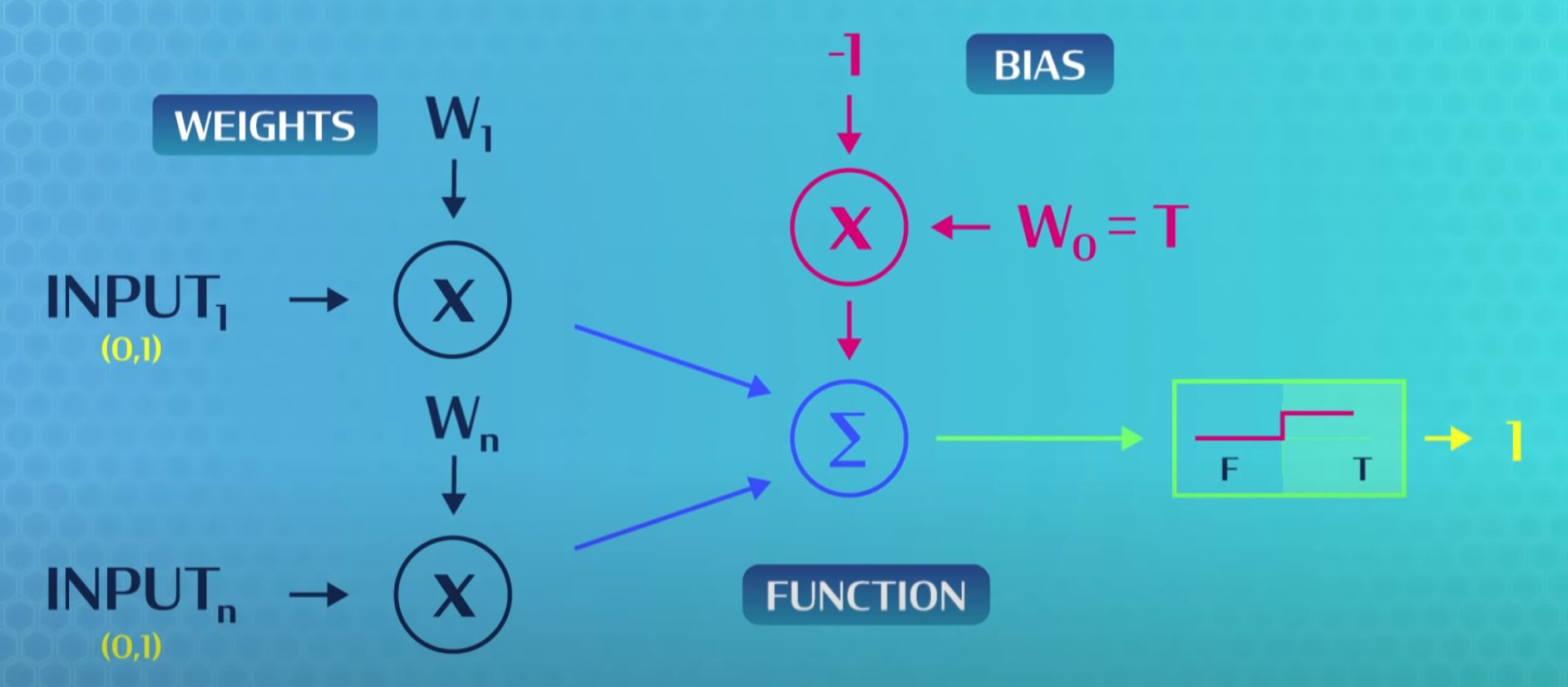
- Inspired by human brains and neurons, psychologist Frank Rosenblatt created the Perceptron to classify whether a shape is a triangle or not a triangle. Now, we just program our computers to behave like neurons. This link explains the neuron structure very well.
- Below is a simple example of how to use a step function as an activation function to either get true or not true (false). The neuron has inputs and weights that are added and if they go above the threshold weight called the bias (can be adjusted), the neuron will output a 1 otherwise a 0.
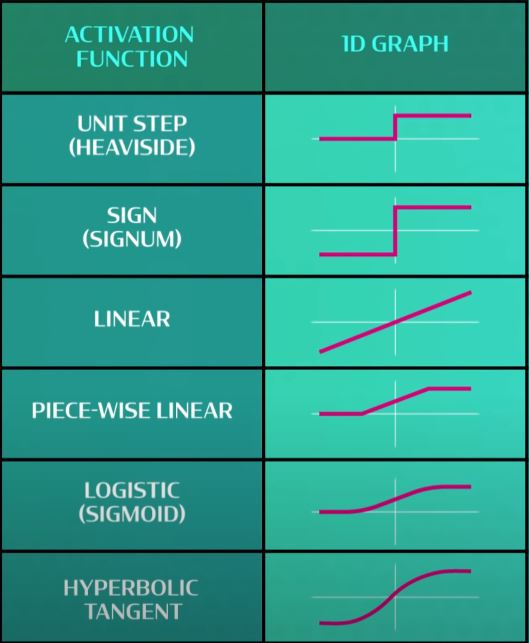
- There are many different kind of functions that we can use. It doesn’t have to be a step function. Some more functions are given below.
- Precision: How much you should trust your program when it says it has found something e.g. it tells you it found 10 triangles and out of those, 8 were actually triangles. So precision is 80%.
- Recall: How much your program can find the thing from the data you’re actually looking for e.g. there were 200 triangles in the data set out of which it found 10 of which 8 were actually triangles. So the recall is 8/200*100 = 4%. That’s a pretty bad recall rate.
Neural Networks and Deep Learning
- What if there is more than one neuron? Our brain has ~100 billion neurons. If we connect a bunch of Perceptrons together, we can create what’s called an artificial neural network.
- Neural networks are one of the most dominant machine learning technologies used today.
- Neural Network Architecture:
- Input Layer
- Output Layer
- Hidden Layers
- A neural network is kind of a block box that does math and spits out an answer.
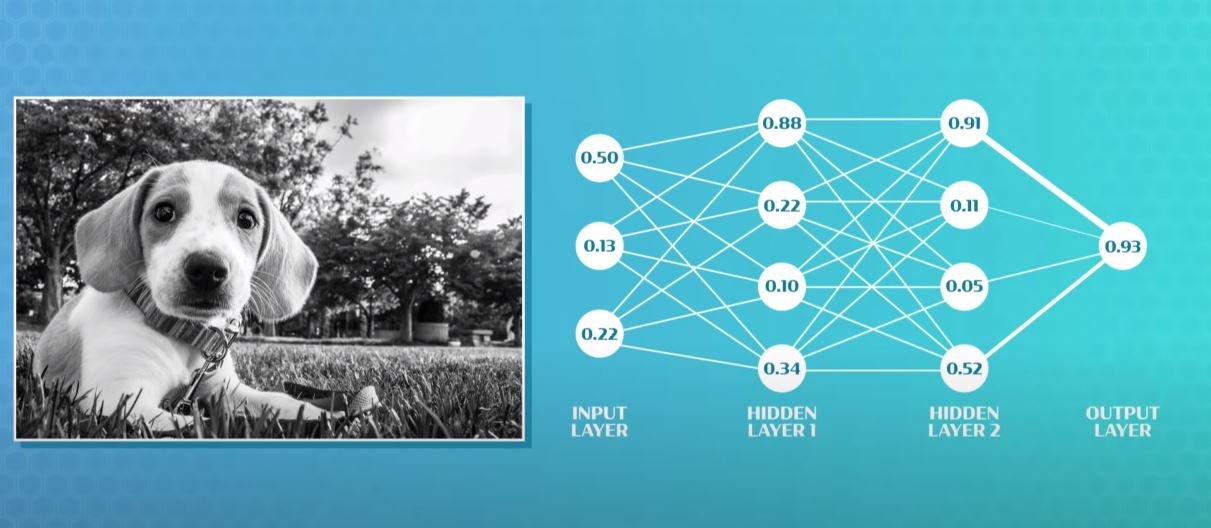
- In the example below, we are trying to detect a dog in a grayscale image. Each number in the input layer represents the brightness of the pixel. Each neuron in the hidden layers may focus on a complexity e.g. the curve of the nose. So it will try to detect the upper part as bright and lower part as dark and apply weights accordingly. It squishes the results between 0 and 1 and passes it to the next layer and so on. When we reach the output layer, if the value is close to 1 then the computer has actually detected a dog.
Training a Neural Network
- If a neural network makes a mistake, this often means that the weights aren’t adjusted correctly. They need to be updated to make better predictions next time.
- Optimization: The task of finding the best weights for a neural network architecture is called optimization.
- Linear regression: Optimization strategy that attempts to model the relationship between two variables by drawing a random linear line between the variables on a graph. The summed distance between the line and each of those data points on the graph is our error. We’ve quantified how big of an error we’ve made. The goal of linear regression is to adjust the line to make the error as small as possible. The resultant line is called the line of best fit as seen below.
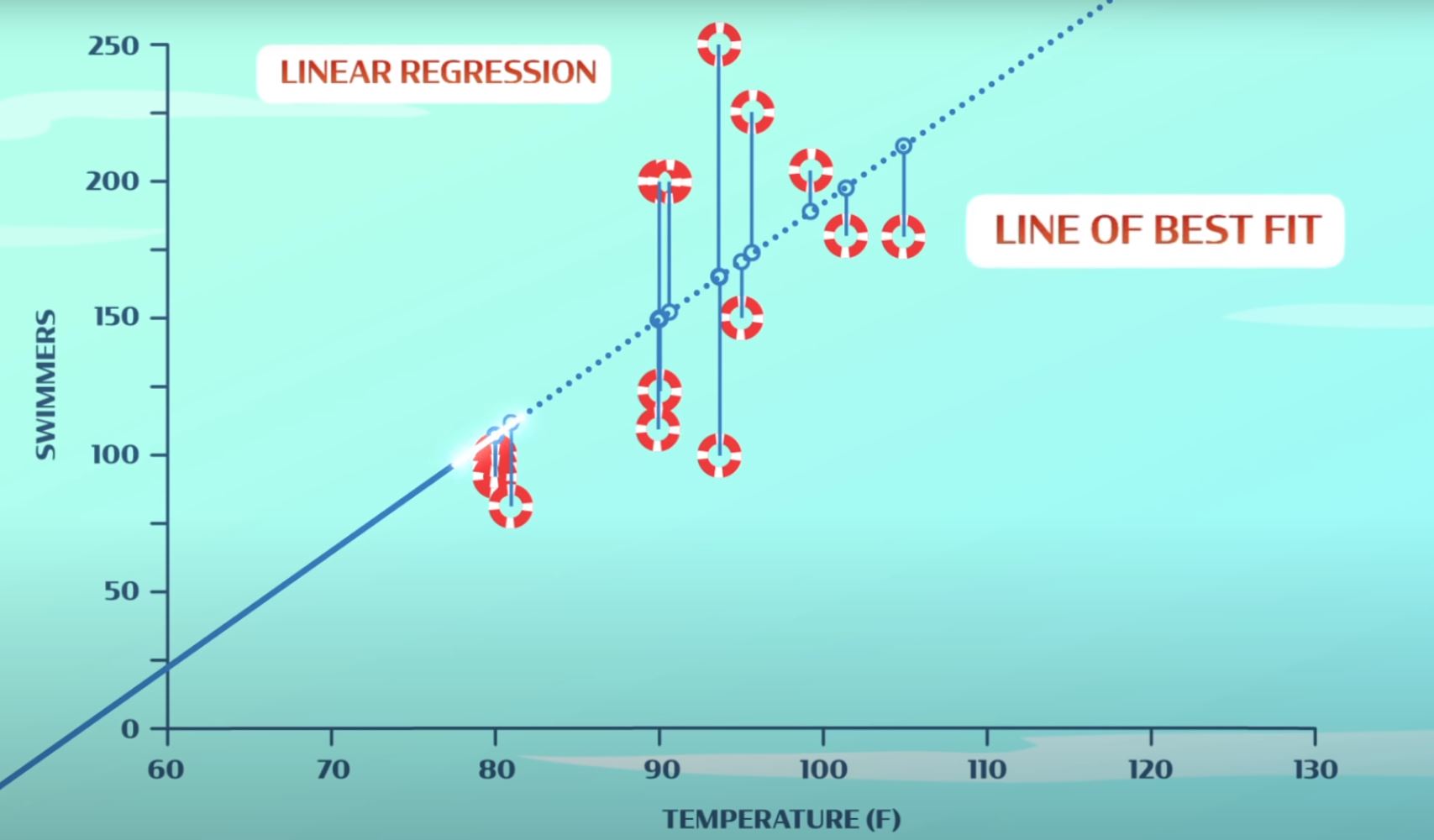
- Some parts of the example above defy logic though. Negative people show up on a cold day and a lot of people show up on a burning hot day. To get more accurate results, we can use more than just temperature and number of people e.g. humidity, rain, etc. However, if we add more features, we can’t visualize it, the optimization gets trickier and fitting the training data is tougher. To overcome this, we use neural networks.
- Example of training:
- Input layer in the above example is humidity, temperature, rain, etc.
- Output layer is the number of swimmers who’ll show up at the pool.
- The neural network starts with random weights.
- To train the network, we’ll provide some data e.g. the input conditions for the first 10 days.
- Simple Example of Day 1: The neurons will multiply the inputs by the weights, adding the result together and passing information from one layer to the next until it reaches the output layer.
- There will be an error between the neural network and the actual people who showed up e.g. 100 people showed up but your network says that 150 people showed up.
- If there are multiple neurons in the output layer, the difference between the predicted answer and the correct answer is more than just one number. In these cases, the error is represented by a loss function.
- Now, we need to adjust the neural network weights so it gives a more accurate value the next time we give similar inputs. Basically, it needs to learn.
- The algorithm to learn is called the back propagation of error or simply backpropagation.
- Where the error is the smallest, it is known as the global optimal solution.
- Where the error is relatively small and not the smallest, it is known as the local optimal solution. Try different points so neural network doesn’t get stuck in a local optimal solution.
- Learning rate: The change in weights each time backpropagation occurs. If it is too much, you might jump over your solution. It it is too small, it might take a lot of time to reach the solution.
- Over time, backpropagation will adjust the neuron weights, so that neural network’s output matches the training data. This is called fitting to the training data.
- If there are a ton of inputs e.g. humidity, temperature, population of the city, per capita income, etc., number of butterflies, that might add to more accurate results but also require more processing power.
- However, the network may train too well. The network may learn the details and noise in the training data to the extent that it negatively impacts performance of new data, this is called overfitting. Keep the neural network simple to avoid overfitting.
- Now provide a new set of inputs to see if the neural network has learnt and predict better.
Training a Neural Network to Read Handwriting
- Step 1: Find or create a labeled dataset to train our neural network.
- Split the data set into training set and testing set.
- Step 2: Create a neural network.
- This involves creating an input layer, hidden layers and an output layer.
- Step 3: Train, test and tweak the code until we feel it is accurate enough.
- Step 4: Scan handwritten pages and use the neural network to convert them into typed text.
Unsupervised Learning
- In supervised learning, we’re triying to build a model to predict an answer or label provided by a teacher.
- In unsupervised learning, instead of a teacher, the world around us is basically providing training labels e.g. can you predict what happens when you throw a tennis ball at a wall? Unsupervised learning is about modelling the world by guesses like this. Babies do a lot of unsupervised learning.
- Recognizing different properties and creating categories for them is called unsupervised clustering. The key assumption is that certain objects are more similar than others and/or share properties e.g. animals that walk on four legs can be a category.
- To construct a model, we answer two key questions:
- what observations can we measure?
- how do we want to represent the world? An assumption is that there are clusters in our data.
- Specifically, there are some number of groups called K-clusters but we don’t know where they are. To help us identify these clusters, we will use K-means clustering algorithm.
- K-means Clustering: K-means clustering is a simple algorithm. It needs a way to compare observations, a way to guess how many clusters exist in the data, and a way to calculate averages for each cluster it predicts. Firstly, it will predict what the world looks like (how many clusters). Secondly, it will update/learn.
- In the example below, we’ll map different flower petals based on their length and width. We believe there are 3 different types (or clusters) of flowers: type 1, type 2 and type 3. These clusters will have three random averages. Our model will try to correct itself by calculating new averages. We can predict that similar flowers will have similar length and width. Using this new prediction and the calculation of averages, we’ll give data points labels of the averages.
Before:
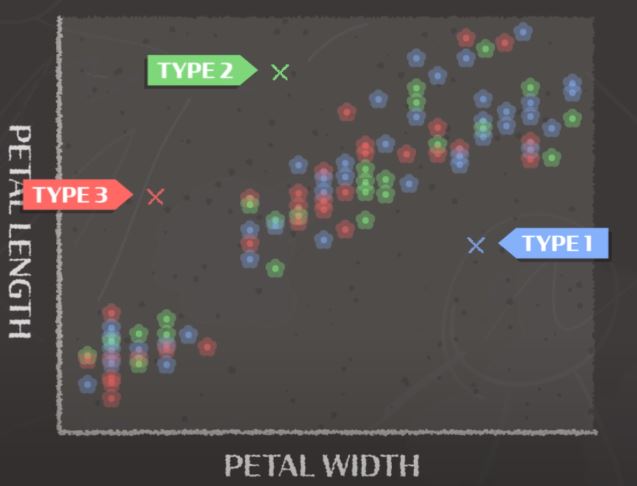
After:

- Another example of unsupervised learning is to sort a bunch of different photos.
- We use representation learning find patterns across many different images. These patterns help us understand what is in the image and how to compare them to each other.
- Representation learning happens in both supervised and unsupervised learning models, so we can do it with or without labels to find patterns in the world.
- Our AI will have learned image representations instead of averages unlike before. After that, the AI will correct itself based on it’s reconstruction. A neural network called autoencoder can take in an image as the input layer and output a whole reconstruction of the original image.
- Unsupervised learning is an huge area of active research.
Natural Language Processing
- Natural Language Processing (NLP) mainly explores two big ideas:
- Natural Language Understanding: how we get meaning out of combination of letters.
- Natural Language Generation: how to generate language from knowledge.
- The key to both problems is understanding the meaning of a word.
- Challenges:
- Words have no meaning on their own.
- Context matters.
- Sometimes we can compare words by looking at the letters they share e.g. if it has morphology i.e. swim-swimmer-swimming, think-thinker-thinking, etc.
- One common way to guess that words have similar meaning is using distributional semantics. In other words, seeing which words appear in the same sentences a lot. One simple technique to do is through count vectors.
- Count Vector: Number of times a word appears in the same article or sentence as other common words. If two words show up in the same sentence, they probably have similar meanings.
- An example would be the comparison of the words: car, cat and felidae. Open up the wikipedia articles of all these and see which ones show up. The cat page and the felidae page will have similar words e.g. species, cat, felidae, pet, etc.
- Count vectors are extremely space intensive so instead, we use a encoder-decoder model. A model that can make internal representations and that can generate predictions - what to remember from a sentence done by the encoder, what to say afterwards done by the decoder e.g. “I love chocolate __” is the sentence and we have to guess the blank. Our encoder can focus on ‘chocolate’ and then pull data which is linked to chocolate (milk, cookies, cake, etc.).
- We can also use recurrent neural networks to predict words in a sentence as well by giving random vector values to words and then training the network to give similar words similar vector values.
- Steps of NLP Example:
- Clean and preprocess data (stemming of morphology words, tokenizing lexical types and tokens, generating unique unknown types, etc.).
- Convert every word into a number.
- Use an embedding matrix to create a large matrix where each row corresponds to a different word. Put random numbers for each word at the start.
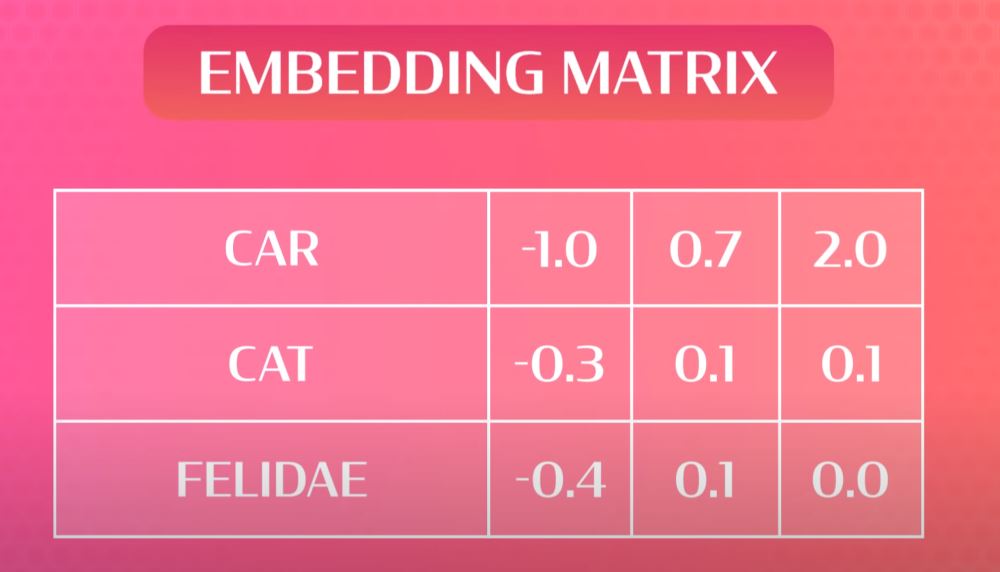
- Use RNN and train the model. By using the sentences given, the model will figure out what to predict next in the sentence.
- Make predictions.
Reinforcement Learning
- Basically, trial and error.
- Reinforcement learning is useful for situations where we want to train AIs to have certain skills we don’t fully understand ourselves e.g. walking is easy but what’s the optimal way to walk? What should the angle be of your foot relative to the ground, what should be the velocity, and so many other variables are involved?
- Reward the AI if it does takes a good step but hard to predict if the step is actually good until the end of the task. This is called the problem of credit assignment.
- After it does successfully complete a task, we can go back and look at which steps were helpful and which weren’t.
- In reinforcement learning, we need a balance between exploitation and exploration.